JS:数据结构与算法
Posted by Mars . Modified at
记录一些算法 & 技巧
Preview
算法的复杂度
基本操作
在普通的计算机上,加减乘除、访问变量(访问基本数据类型的变量)、给变量赋值等都可以看作基本操作。
对基本操作的次数统计或是估测,可以作为评判算法用时的指标。
不同的基本操作,其实执行用时是不同的(除法比加法用时长),这种不同在计算时间复杂度的时候因过小被忽略。
数据规模
衡量一个算法的快慢,一定要考虑数据规模的大小。
所谓数据规模,一般指输入的数字个数、输入中给出的图的点数与边数等等。
一个数据规模,一般用一个字母来表示(m、n等)。
时间复杂度
程序执行的用时随数据规模而增长的趋势,叫做时间复杂度。
时间复杂度分为最坏时间复杂度和平均时间复杂度。
最坏时间复杂度,即每个输入规模下用时最长的输入对应的时间复杂度。在算法竞赛中,由于输入可以在给定的数据范围内任意给定,我们为保证算法能够通过某个数据范围内的任何数据,一般考虑最坏时间复杂度。
平均(期望)时间复杂度,即每个输入规模下所有可能输入对应用时的平均值的复杂度(随机输入下期望用时的复杂度)。
算法如何高效
- 计算机解决问题,本质上都是穷举出所有可能结果,然后进行比较选择;
- 计算的问题可能性越多,就从本质上决定了计算的复杂度越大;
- 提升算法效率,一般只有以下几个途径:
- 通过人进行逻辑分析,充分避免无意义的计算步骤(剪枝);
- 通过充分利用已经计算的结果,避免重复计算(记忆化);
- 通过合并操作,减少高成本的操作次数。
思路相关
一些思考方向
- 查看解本身,或者与解有关的因变量,是否具有单调性。具有单调性的问题可以用二分查找求解;
- 求解空间上连续子区间的问题,考虑滑动窗口法;
- 自变量与因变量之间存在负相关(一增一减),考虑从两端开始相向而行的双指针法;
- 问题明显与状态相关,可以清晰地用几个参数定义问题的状态,而且前后状态之间存在转移关系,考虑动态规划。特别地,当状态空间非常小时(大约数万),考虑用二进制进行状态压缩;
- 对比分析每一步的几种决策,可以消除掉一些非优策略。当问题存在唯一的局部最优策略,那么整体最优结果一定由这个局部最优策略得来,可以使用贪心算法;
- 问题可以分解为两个或多个子问题,且问题小到一定规模结果是显然可得的,考虑分治法;
- 问题状态空间较小(例如只有<= 16位的长度),可以直接进行枚举。特别地,可以用二进制数表示每一个状态,从而用二进制数代表状态,进行枚举;
- 问题数据量有关的提示信息:
≤ 20: 可以是指数级算法。如:回溯等;≤ 2*10^4:复杂度至少为O(n2)的方法,如:动态规划等。;≥ 10^5:复杂度至少为O(n*logn)的方法。如:二分查找、滑动窗口、贪心等。
关注点
- 达成目标的条件:题目的目标是什么,什么情况下就达成了目标,达成目标的条件是否可以等价转化;
- 不变量:如果在变化过程中存在恒定不变的变量、点或序列等,可能是求解的关键;
- 转移关系:随着变量的改变,前后二者是否存在可以互相转移的关系;
- 多个约束条件的耦合性:如果同时存在多个约束条件,考察它们之间是否存在耦合性,如果无耦合可以将它们分开。例如:左右两侧分别进行一次遍历;
- 可操作的方式:如果题目给你一定的权限进行某种操作,尽可能枚举所有操作,观察它们对结果的影响;
- 选择唯一的情况:当可以进行多种选择时,关注选择情况受限(或只能进行唯一的选择)的情况,它可能是动态规划等方式解决问题的起点;
- 映射不变性:给定的元素编号、索引等,在经过一次变换后,如果仍保持一一映射关系,且某些基本性质并未发生改变,可以考虑将利用映射关系,分解问题为子问题;
- 覆盖:状态之间是否存在覆盖,从而可以去掉一些情况;
- 操作是否有效: 每种操作,需要观察其后果,是否等价于其他操作,或者是无效操作;
注意事项
- 正确可行的思路是核心。在没有形成完整的思路之前,不要开始写程序;
- 读题。读题。读题。(充分理解题目要求);
- 充分构造边界条件下的测试用例,全通过后再提交。
雷点&坑点
- 关注是否存在负数节点,出现负元素,很多算法都有所限制,尤其和最优化相关;
- 二分查找的数据范围。一般不要使用
((l+r) >> 1)这种找中点的方法,容易溢出。要使用Math.floor((l+r)/2);
栈、队列(优先队列)和哈希表
栈
栈是只能在一端进出,有”先进后出(FIFO)”特性的数据结构。
★单调栈
单调栈:栈内的元素索引值单调递增,且元素值从底向顶也单调递增或单调递减。
单调栈同普通栈一样,元素只能在栈顶进出。
单调栈的目的是,随着原序列的遍历,维护一个局部最优的子序列。属于贪心算法的工具。
单调栈可以用来解决:
- 查找数组中每个元素下一个大于(或小于)自身的值;
- 按索引顺序,查找具有最大跨度的上升(下降)元素对;
- △查找最小或最大子序列。
有关用法2的详细解释,见最大宽度坡题解。
队列
队列是”先进先出(FIFO)”的数据结构。
单调队列
单调队列:队列中元素的索引值单调递增,且队列中的元素值单调也递增(或递减)。
单调队列与普通队列不同,一般为双端队列。元素可以在两侧出队,而只能在队尾入队。
Out:
Head <- [a,b,c,d] -> Tail;In:
[a,b,c,d] <- Tail
单调队列在滑动窗口中应用,可以获取窗口内的最大、最小值。操作如下:
- 设置单调队列queue,初始值为空;(假设我们要保存的是窗口的最大值,queue为单调递减队列)
- 假设窗口左指针为left,右指针为right。当窗口扩大时,right向右移动,此时判断新加入窗口的元素
arr[right+1]与queue队尾的元素大小关系:- 如果
arr[right+1] > queue[queue.length-1],说明有新的最大值加入,这里因为queue中的元素都比新加入的元素更靠前,因此在left到达right+1位置之前queue[queue.length-1]绝不可能再成为最大值,因此可以将它在队尾删除; - 同理,删除后还需要对下一个队尾值进行比较删除操作,直到队空或队尾元素值大于等于新值,将新值从队尾加入队列;(等于的情况需要保留,因为之前加入的值仍然是最大值。)
- 这样就保证了单调队列的两个特性:索引和值都单调递增。
- 如果
- 当窗口需要缩小,left向右移动,事项如下:
- 在窗口中不存在的元素,需要从队列中删除;
- 因为left <= right,当前要删除的left元素最先加入队列,因此它要么在队列的最前面,要么已经被后来的最大值淘汰,被从队尾删除掉;
- 此时只需判断队首元素是否是left对应的元素,如果是则将它从队首出队,如果不是则不用做任何操作。
- 每次窗口移动,队首的元素就是当前窗口内的最大值。
哈希表
适用于:计数类问题。哈希表可以快速判断一个值是否出现在集合中,而避免了每次都要遍历查找。
缺点是空间复杂度高,是以空间换时间的方法。
哈希结构:数组、对象、Set、Map
哈希表计数去重
使用哈希表计数两数组合,如何能不重复?
给出一个数组arr,求数组中子序列 [a,b] 加和 a+b=target 的组合数。使用暴力解法时间复杂度为
O(n^2),可以使用两个嵌套for循环,通过索引来实现无重复计数。使用一个哈希表map,可以实现
O(n)复杂度的算法。但是如果采用先将数组元素添加到map统计数目,后遍历map计算组合数的方式,计算的组合数将包含重复情况:例如: map = {1: 3, 2: 3} ,target = 3,遍历map时,会得到
[1,2]+[2,1]共计18种组合,实际上只有9种。可以采用边统计,边计数的方式,避免这种重复计数的情形:
- 每次将元素i放入map前,先计算 map 中 target-i 的数目num,将其加入计数结果count;
- 将元素放入map,它对应在map中的数目+1.
这样做可以避免重复计数(
[a,b]和[b,a])的原因是:如果a和b是一对待计入组合,那么按照这种依次加入的方式,他们加入map一定有先后顺序。我们只在二者中后加入map的一方加入map的时候计数。因为所有元素最终一定都被添加到map,他们之间两两存在先后顺序,也就是说如果存在任意组合需要被计入,只会在组合元素最后一次被添加的时候计数,也就是只会计数一次。
ST表
ST表的功能与复杂度
ST表(Sparse Table,稀疏表),是一种基于倍增思想的数据结构。
ST表经常用于解决高效查询区间最值问题(RMQ)。
ST表可以在O(n*log_n)时间复杂度进行建立,然后在O(1)时间复杂度内实现对[l,r]区间内最值的查询。
实际上,ST表可以解决的问题叫做可重复贡献性问题。
任何一个操作
opt,如果x opt x === x,则opt叫做可重复贡献操作,也就是对同一参数多次执行,不影响计算结果。
ST表的原理与结构
ST表基于以下原理实现:
- 任何一个区间
[l,r],都能找到两个长度len = 2^i (2^i ∈ [1, r-l+1])的子区间[l,a]和[b,r](a,b在[l,r]区间内); - 我们可以以
2的幂为区间长度,预先计算出各个区间的最值; [l,r]区间内的整体最值结果,与分别对子区间[l,a]和[b,r]求最值,然后再联合求最值的结果相同。
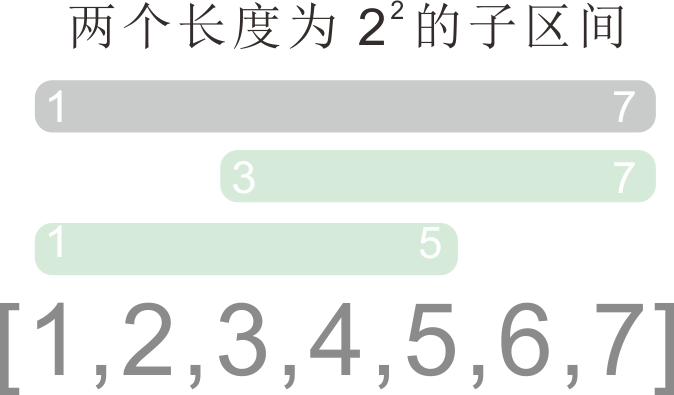
ST表的处理过程:
- 预处理,建立ST表:
- 设
d[i][j]为从i开始的,长度为2^j的闭区间[i, i+2^j-1]的最值结果; - 使用动态规划,计算出原区间
[l,r]的全部d[i][j]值; - 对于区间
[l,r],i的取值范围为[1,r],j的取值范围为[0, log(r-l+1)]。
- 设
- 查询
[l,r]区间的最值:- 将
[l,r]区间分为两个子区间[l,a]和[b,r]。为了让子区间最大程度地重叠,子区间长度尽可能靠近r-l+1,因此len = 2^j的指数j选取为j = ⌊ log(r-l+1) ⌋; - 获取
d[l][j]和d[r-2^j+1][j]的值,取二者的最值即为结果。
- 将

ST表的实现
class ST {
constructor(arr = []) {
let JMAX = Math.floor(Math.log2(arr.length)) + 1;
let d = new Array(arr.length).fill(0).map(i => new Array(JMAX).fill(0));
arr.forEach((i, idx) => {
d[idx][0] = i;
});
for (let j = 1; j <= JMAX; j++) {
for (let i = 0; i + (1 << j) - 1 < arr.length; i++) {
// [i, i+2^j-1] --> [i, i+2^(j-1)-1] + [i+2^(j-1), i+2^j-1]
// d[i][j] --> d[i][j-1] + d[i+2^(j-1)][j-1];
// 动态规划:[i,j]用到j-1列的数据,因此计算顺序是先列后行。
d[i][j] = Math.max(d[i][j - 1], d[i + (1 << (j - 1))][j - 1]); // 这里执行对应的可重复贡献逻辑: max, min, gcd...
}
}
this.d = d;
}
query(l, r) {
let j = Math.floor(Math.log2(r - l + 1));
return Math.max(this.d[l][j], this.d[r - (1 << j) + 1][j]);
}
}
堆(优先队列)
数组
差分数组
定义和适用情况
差分数组:对于一个源数组arr,差分数组diff[i]定义如下:
diff[0] = 0;diff[i] = arr[i] - arr[i-1]; (i > 0)
差分数组主要用于对原数组子区间内元素,进行统一增减操作的情况,将区间内的统一变化,转化为两个端点的变化。
可以将数组操作转化为哈希表记录端点变化的操作,降低复杂度。
差分数组的性质
对于一个数组arr,计算它的差分数组diff,如果它的子区间[a,b]进行统一的增减n的操作,diff数组的变化如下:
- 统一增大n:
diff[a]增大n,diff[b+1]减小n,其他不变; - 统一减小n:
diff[a]减小n,diff[b+1]增大n,其他不变;
也就是说,区间
[a,b]同时增减操作,只影响差分数组的区间头位置a和尾位置+1位置b+1,diff[a]与变化方向相同,diff[b+1]与变化方向相反,变化值绝对值相同都为n。
从另一个角度考虑,在对区间[a,b]进行了统一增加n操作后,diff的[a,b]区间前缀和统一增加了n,而其他位置前缀和不变。
因为+n发生在
diff[a]位置,-n发生在diff[b+1]位置,而中间的元素不变。所以
[a,b]区间内前缀和都统一增加了n,而到b+1位置恢复,b+1之后的前缀和没有变化。
差分数组的好处
差分数组将一个区间内的操作,转化为在两个端点的操作,省去了遍历整个区间的过程,减少了时间复杂度。
差分数组应用实例:
前缀和
对于一个数组arr的索引i,前缀和也就是求区间[0,i]中数组所有元素的和。
对于一个子数组(连续)的所有元素之和,等于它首尾位置前缀和之差。这有时可以用于降低复杂度。
子数组
子数组是一个数组
arr中索引连续的元素组成的数组。
子树组类题目,一般情况是需要统计符合某种规则的子数组数目。
一个长度为n的数组,它的全部子数组数目为n *(n+1)/ 2,为n^2量级。因此当数据量较大(一般大于30000)时,暴力法无效。
当暴力法无效时,就需要一些特殊的判断技巧,以降低复杂度。这时可以观察题目要求规则的特点,枚举子数组中比较有特点的某个元素位置,从而寻找子数组数目。
一般有以下两种情况:
- 枚举子数组左、右边界:比如统计以某个字符作为结尾的子数组数目,我们枚举找到这个字符的位置,以它为结尾的子数组数目,等于它前面元素的数目
n+1; - 枚举子数组中某个特殊元素位置,可以依此将子数组分为左右两部分:比如约定了子数组的最大值、最小值区间范围时,我们直接枚举以某个元素为最大、最小值的子区间数目。

最值在某一区间范围[l,r]的子数组个数
现在给定我们一个区间[l,r],让我们求出最大(小)值落在这个区间的,arr的子数组的个数。
基于上节思路,现在再多考虑一些细节:
- 枚举哪个位置?如果我们选择从左到右遍历原数组,因为我们已遍历的区间在当前位置
i的左侧,要实现O(n)的算法,只能认为我们当前枚举的位置是区间的右边界; - **如何判断符合要求子区间的数目,以及取舍?
- 要实现
O(n)的算法,我们每次只能考虑当前正在遍历的这个元素arr[i],利用它的值来判断以arr[i]为右边界的一系列区间的保留与舍弃**,因此要设定一个对当前元素的判定条件; - 已经遍历的部分,我们记录符合条件的元素出现的长度
len,以当前位置arr[i]为结尾的符合要求子数组个数,就等于len+1。(见上节图); - 对于取区间最大值的问题,符合要求的元素为
arr[i] <= MAX,我们必须保证计入len的元素都满足这一条件,因此我们将原区间[l,r]划分为[~,l-1]和[~,r]两个向左的区间差; - 对于取区间最小值的问题,符合要求的元素为
arr[i] >= MIN,我们必须保证计入len的元素都满足这一条件,因此我们将原区间[l,r]划分为[l,~]和[r+1,~]两个向左的区间差;
- 要实现

代码实现:
// 求子数组最小值满足[l,r]的个数:
function minValueBetweenCnt(arr, l ,r) {
// [1,3,2,4,5,10,6,3,1,5,4,9,12,1]
// [3,6]
// min >= 3 && min <= 6
// (min >= 3) - (min >= 7) 区间取最小值,划分为两个向右的区间差
function cntMinValueLargerThan(e) {
let cur = 0;
let res = 0;
for (let i of arr) {
// 枚举子数组右边界位置
if (i >= e) cur += 1; // 当满足要求,连续出现的符合要求元素数 +1
else cur = 0; // 不满足要求,连续出现的符合要求元素数 归0
res += cur;
}
return res;
}
return cntMinValueLargerThan(l) - cntMinValueLargerThan(r+1);
}
// 求子数组最大值满足[l,r]的个数:(原理相同)
function maxValueBetween(arr, l, r) {
// [l,r]
// [~,r] - [~,l-1]
function cntMaxValueSmallerThan(e) {
let res = 0;
let cur = 0;
for (let i of arr) {
if (i > e) cur = 0;
else cur += 1;
res += cur;
}
return res;
}
return cntMaxValueSmallerThan(r) - cntMaxValueSmallerThan(l-1);
}
动态前缀和:树状数组
树状数组(Binary Indexed Array)
树状数组(Binary Indexed Array,BIT)的功能,是求解某一数组的动态前缀和。
它巧妙地利用了数组索引的二进制表示信息,实现了在O(log_n)时间复杂度,实现对数组arr的任意位置前缀和的修改和查询操作。
同样,区间和的查询,相当于两次前缀和的查询,因此也可以在O(log_n)时间复杂度实现区间和的查询操作。
树状数组建立的过程,复杂度是O(n * log_n)。
动态前缀和有什么用?
动态前缀和可以随着原数组的遍历,对前缀数组进行动态修改,从而更快找到我们想要的信息。
树状数组的结构
- 树状数组的索引从
1开始; - 树状数组的每一个位置,都保存着原数组
arr某一区间的加和; bit[i]具体保存的是哪一个区间的信息,与索引i有关;- 从索引
i二进制表示最末位开始,一直向前直到找到第一个1位,区间所表示的二进制数len = lowbit(i),就是bit[i]所表示的向前区间长度(包含当前位置); - 某一位置
i所表示区间的前一个区间元素位置:i - lowbit(i); - 某一位置
i所表示区间的上层覆盖区间的元素位置:i + lowbit(i)。

树状数组的功能
[1, i]区间前缀和的查询query(i);- 原数组
i位置数据的更新update(i, diff);(diff为更新的增量) lowbit(i),计算i位置的区间长度len;

树状数组的实现
// Mars 2022.02
class BIT {
constructor(arr = []){
// arr[i] -> bit[i+1]
this.bit = new Array(arr.length+1).fill(0);
arr.forEach((i,idx) => this.update(idx, i));
}
lowBit(i) {
return i & (-i);
}
update(i, diff) {
// update arr[i] with delta <diff>.
let c = i + 1;
while (c < this.bit.length) {
// 不断向上寻找覆盖区间,并更新;
this.bit[c] += diff;
c += this.lowBit(c);
}
}
query(i) {
// query prefix sum of [0, i]
if (i >= this.bit.length-1) {
console.warn(`index exceed the limit.`);
return;
}
let c = i + 1;
let r = 0;
while (c > 0) {
// 不断向前寻找区间,并加和;
r += this.bit[c];
c -= this.lowBit(c);
}
return r;
}
}
线段树
线段树将一个数组的区间计算信息,预先计算并保存在一个树状结构中,降低后续数组区间查询和更新数据的复杂度。
线段树可以在O(n*log_n)时间复杂度内建立,然后在O(log_n)的时间复杂度内实现单点修改、区间修改、区间查询(区间求和,求区间最大值,求区间最小值)等操作。
线段树适用于需要频繁对数组进行区间信息查询,且频繁对数组进行更新的情况。
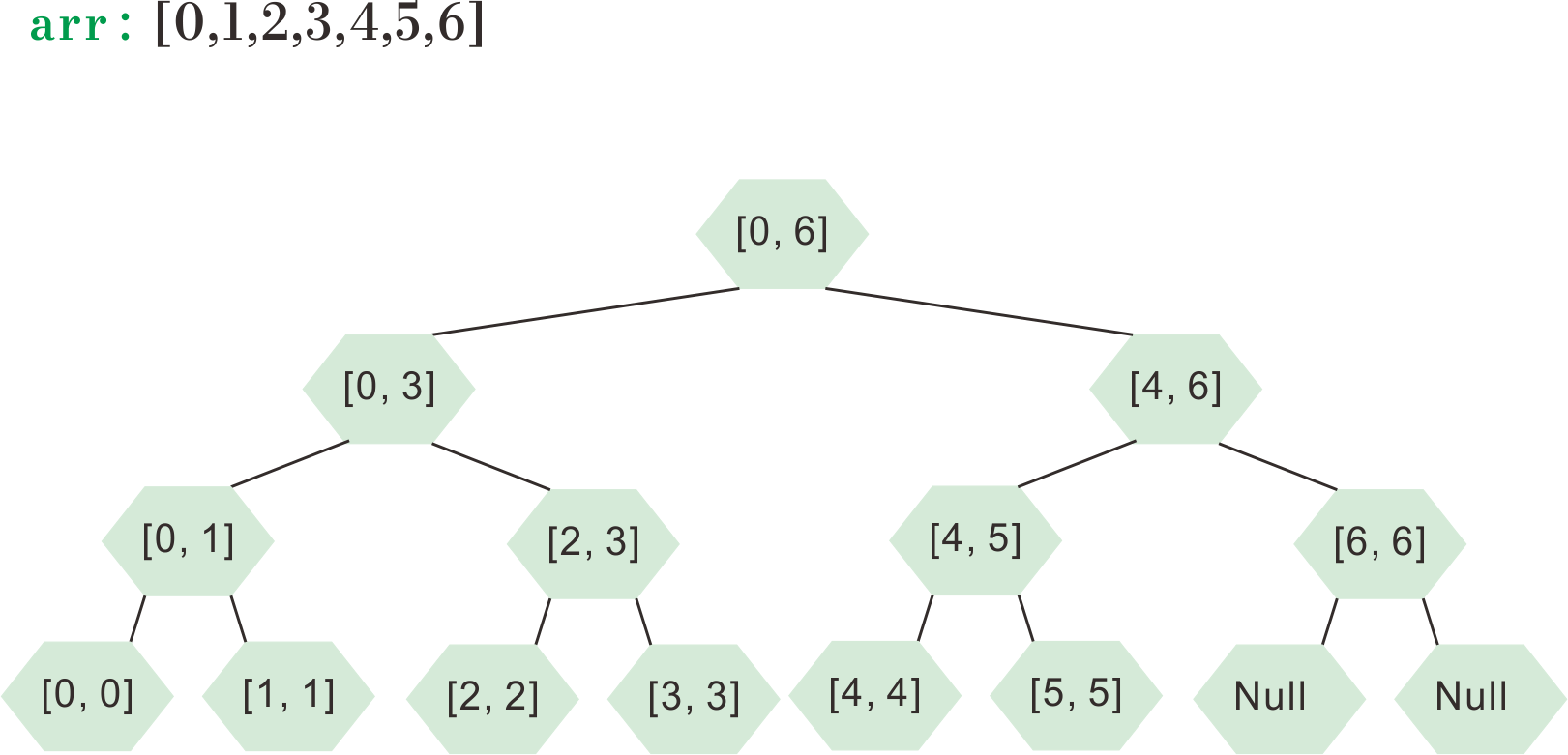
线段树的结构
- 线段树是二叉树形式的数据结构,可以用Node或数组形式表示;
- 线段树的每一个节点,代表原数组一个区间的信息。例如:节点A可以表示
[0,3]区间内,原数组的元素加和结果; - 线段树节点的子节点,记录父节点区间,从中间点拆分而成的子区间信息,中间点属于左子节点还是右子节点均可,可以自行约定。
例如:节点A表示
[0,3]区间,我们约定取中间点为m = Math.floor((l+r)/2),且左子节点保存[left, m]的区间,右子节点保存[m+1, right]区间,那么A的左子节点保存[0,1]区间信息,右子节点保存[2,3]区间信息。 - 线段树的叶子节点,就是区间长度为1的结果,也就是保存了原数组的各个元素值。
constructor(arr = []) {
this.arr = arr;
this.tree = new Array(4 * this.arr.length).fill(null);
this.build();
}
线段树的生成 build
使用递归的方式生成。
- 线段树需要的数组空间不好计算,根据渐进公式可以设其长度为
4 * n(n为原数组长度); - 与建堆一样,
i的左子节点索引为2i+1,右子节点为2i+2; - 递归函数需要记录的参数:当前树节点的索引
idx,当前节点代表的区间左边界left,右边界right; - 递归出口条件:
left === right: 叶子节点,返回arr[left];left > right: 空节点,返回null。
- 函数体内,将区间按约定的中点分隔方式,分隔并递归调用即可。
build(idx = 0, start = 0, end = this.arr.length - 1) {
if (start === end) {
this.tree[idx] = arr[start];
return;
}
let leftIdx = 2 * idx + 1;
let rightIdx = 2 * idx + 2;
let m = Math.floor((start + end) / 2);
// [start, m] [m+1, end]
this.build(leftIdx, start, m);
this.build(rightIdx, m + 1, end);
this.tree[idx] = this.tree[leftIdx] + this.tree[rightIdx];
}
线段树的更新 update
更新arr[i] = val,只需要对线段树的arr[i]所处的叶子节点,及其各祖先节点进行更新即可。其他节点不受影响。
- 判断更新前后的值是否相同,相同则无需更新,直接结束;
- 计算要更新的差值,
delta = val - arr[i]; - 递归遍历线段树,判断更新的位置
i是否位于[left, right]区间内,是则在当前节点的值上加上差值delta,并对子区间递归调用。不在区间内则直接返回;
update(arrIdx, val) {
if (val === this.arr[arrIdx]) return;
let delta = val - this.arr[arrIdx];
this.arr[arrIdx] = val; // refresh arr self
// refresh tree
this._treeUpdate(arrIdx, delta);
}
_treeUpdate(arrIdx, delta, idx = 0, start = 0, end = this.arr.length - 1) {
if (arrIdx < start || arrIdx > end) return;
if (start === end) {
this.tree[idx] += delta;
return;
}
this.tree[idx] += delta;
let leftIdx = 2 * idx + 1;
let rightIdx = 2 * idx + 2;
let m = Math.floor((start + end) / 2);
this._treeUpdate(arrIdx, delta, leftIdx, start, m);
this._treeUpdate(arrIdx, delta, rightIdx, m + 1, end);
}
线段树的查询 query
对原数组某个子区间[l,r]内的结果进行查询:
- 分治思想,递归将原数组拆分,直到区间两端节点与线段树某一节点的两个端点相同,将线段树中结果加和计入结果中;
- 返回加和结果。
注意:这里在递归对区间进行拆分的时候,需要按照线段树节点区间的中点m位置来分情况讨论:
- 当
m位于查询区间左侧,只需要对右子节点进行递归查询,且区间不用分割; - 当
m位于查询区间右侧,只需要对左子节点进行递归查询,且区间不用分割; - 当
m位于查询区间内部,需要将区间分割成[l, m]和[m+1, r],对左右子节点分别进行递归查询、求和。
query(start = 0, end = this.arr.length - 1) {
if (start > end) {
console.warn(`Start must be smaller than or equal to End.`);
return null;
}
return this._query(start, end);
}
_query(qStart, qEnd, idx = 0, start = 0, end = this.arr.length - 1, res = [0]) {
if (qStart === start && qEnd === end) {
res[0] += this.tree[idx];
return res[0];
}
let leftIdx = 2 * idx + 1;
let rightIdx = 2 * idx + 2;
let m = Math.floor((start + end) / 2); // [start, m] [m+1, end]
if (m >= qEnd) {
this._query(qStart, qEnd, leftIdx, start, m, res);
} else if (m+1 <= qStart) {
this._query(qStart, qEnd, rightIdx, m+1, end, res);
} else {
this._query(qStart, m, leftIdx, start, m, res);
this._query(m+1, qEnd, rightIdx, m+1, end, res);
}
return res[0];
}
哈希数组
哈希数组,数组的每一个元素为一个哈希表,适用于需要保存数组元素各个变化状态的情况。
数组元素arr[i]每次变化,将变化存储在i对应位置的哈希表中,需要时从哈希表中取出对应状态的值即可。这样没有变化的元素不会被额外存储,造成空间浪费。
树:二叉树、BST、Trie
二叉树 Binary Tree
二叉树的特点
二叉树是一种特殊的图,可以将二叉树看成有向图:
- 除了根节点外,它的每个节点入度都是1;
- 除了叶子节点外,它的每个节点出度都为2;
- 全部节点的入度加和,等于出度加和。
二叉树的前、中、后序遍历
二叉树前中后序遍历的迭代的统一写法思路:
- 使用一个栈stk来保存遍历的路径,使用Res数组记录结果;
- 因为栈的入栈与出栈顺序相反,所以入栈顺序需要与前、中、后序遍历的顺序相反(前序: 中→左→右,入栈: 右→左→中);
- 只有在中间元素出栈的时候才记录结果到res数组;
- 在中间元素后面添加一个null元素,作为它出现在中间位且没被res数组记录的标志,一旦在出栈过程中出现null,说明此时应该向res添加记录下一个元素;
- 直到栈stk为空,结束迭代。
例如:
// 后序遍历:
// 遍历:左右中
// 入栈:中右左
function postOrderIterate(root){
let stk = [root];
let res = [];
while(stk.length !== 0){
let cur = stk.pop();
if(cur === null){
res.push(stk.pop().value);
continue;
}
stk.push(cur, null); // 中 (记录标志为null)
if(cur.right) stk.push(cur.right); // 右
if(cur.left) stk.push(cur.left); // 左
}
return res;
}
二叉树的序列化与反序列化
什么是序列化
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。
通俗地讲,序列化就是将一种数据结构,转化为字符串等不同环境通用的中间格式的过程。需要注意的是,序列化后的结果,在另一个执行环境中进行复原后(反序列化),其复原结果必须与原数据一致,没有歧义。
二叉树该如何序列化
- 如果树中不存在重复的元素,那么知道了二叉树的三种遍历结果中的任意两种,即可还原出原有的树结构。
- 如果存在重复元素,则需要对二叉树的空节点也进行输出,用一个特殊符号表示(将二叉树转化为扩充二叉树),然后进行先序或后序遍历(中序无法确定根节点位置,故不行)。
扩充二叉树的先序、后序遍历结果,与二叉树的节点是一一对应的,因此恢复的结果也是唯一的。
二叉树的反序列化
如何对含空节点标记的二叉树的先序遍历序列化结果,进行反序列化(复原)?
以'1234###5###'为例:
- 先序遍历结果以
中-左-右顺序出现,所以最左侧的值一定是当前根节点的值; - 先序遍历会沿着一条路径一直向左探索,直到遇见叶子节点;
- 我们用一个栈
stk保存路径,每次从序列拿到新的节点值val,我们根据val的值新建一个节点Node(可能是空节点null):- 如果栈顶节点
top的左子节点为空,则将val填充到top的左子节点; - 如果栈顶节点
top的左子节点不为空,则将val填充到top的右子节点;
- 如果栈顶节点
- 如果当前值
val不是代表空节点的占位符#,则将新插入的节点入栈,记录下来; - 循环判断栈顶元素的左右子节点是否都被填充过,如果是,则对栈顶元素进行出栈,以保证栈顶是下一个待填充的节点;
- 最后返回根节点即可。
function _buildFromPreorderSerialzation(str) {
// Mars 2022.02
if (str.length === 1 && str[0] === '#') return null;
str = str.split('');
let res = new Node(+str[0], '$', '$');
let stk = [res];
for (let i = 1; i < str.length; i++) {
let cur = str[i] === '#' ? null : new Node(+str[i], '$', '$');
if (stk[stk.length - 1].left === '$') stk[stk.length - 1].left = cur;
else stk[stk.length - 1].right = cur;
if (cur !== null) stk.push(cur);
while (stk.length > 0 && stk[stk.length - 1].right !== '$' && stk[stk.length - 1].left !== '$') stk.pop();
}
return res;
}
字典树 Trie
字典树由字符串生成,形式是嵌套的哈希表形成的树结构。
字典树以输入字符串的每位字母为键名,
字典树可以用于文本推断、自动填充等场景。
时间复杂度:
- 构建、插入: O(n)
- 查询: O(n)
空间复杂度:
- 构建、插入: O(n)
- 查询: O(1)
构建字典树:前缀、后缀

构建前缀、后缀字典树Trie的步骤:
- 初始化:设置根节点为一个空哈希表(Map或空对象),也可以在内部设置各种结尾的标志符;
- 插入操作:从插入字符串的0位置(前缀)或末尾位置(后缀)开始,向后(前)遍历,设置初始哈希表cur为根节点,对于每一位的字符letter,执行如下操作:
- ① 在当前哈希表中查找letter键名,如果不存在,则在cur中为letter创建一个新哈希表;
- ② 将cur指向letter对应的哈希表,在letter哈希表设置对应的结束标志为true(如果构建前缀树,每步都设置前缀结束标志为true,最后词尾设置词汇结束标志true);
- ③ 继续遍历,直到字符串尽头,完成插入;
- 查询操作:从插入字符串的0位置(前缀)或末尾位置(后缀)开始,向后(前)遍历,设置初始哈希表cur为根节点,对于被查询字符串query每一位的字符letter,执行如下操作:
- ① 在当前哈希表中查找letter键名,如果不存在,则说明没有此查询字符串,返回false结束;
- ② 将cur指向letter对应的哈希表,继续查询;
- ③ query全部查询完毕后,判断此时cur中各结束标志是否为true(比如查询前缀query,那么此时前缀结束标志应该是True),如果为true则返回ture,否则返回false。
并查集
定义
并查集是一种抽象数据类型,它操作一组互不相交的集合,可进行高效集合合并和查询两个元素是否在同一集合的操作。
并查集解决的是图的动态连通性问题。即在动态过程中,判断一个图中存在几个连通分量。
应用
- 判断一个图中连通分量的个数;
基本思路
- 一个集合用一个代表元素来表示,称为代表元。判断两个集合是否相同,被简化为判断两个集合的代表元是否相同;
- 一个集合被组织成一个树形结构,代表元是这个树的根元素;
- 集合中的每个元素
x,具有根据x本身访问它父元素的途径parent(x); - 根元素的
parent,指向它自己,也就是parent(x) = x; - 查找一个元素
x的代表元,只需要不断迭代查询元素的parent(x),即可最终找到集合的根元素;
并查集的方法
- 初始化:每个元素的父节点各自指向自身,因为它们独立组成集合,还没有合并;
- 查询:两个元素是否在同一集合中;
- 合并:将两个集合合并成一个;
- 获取集合中子集合个数:获取当前并查集中子集合的个数。
并查集的优化
记录集合高度
对于每个集合,记录集合树的高度rank,在合并的时候,将较小rank的集合连接到较大rank的集合树上,可以减小合并后树的高度。
路径压缩
对于每次查询,如果查询到元素a所在集合的根元素是root_A,那么直接把a连接在root_A上,这样下次查询可以省去多级遍历的过程。
路径压缩后,集合树的高度可能有所变化,但是一般为简单起见,路径压缩后树的高度rank保持不变。
并查集的实现
可以用数组实现,也可以用哈希表。
用数组实现,是每个数组位置代表一个元素,同时定义parent数组和rank数组,记录每个位置的元素的父元素和它为根节点树的高度。
用哈希表实现,是每个元素的值作为键名,键值为一个对象,将parent和rank储存在其中。
// HashMap Implementation
class BingChaJi {
constructor(vals = []) {
this.map = new Map();
for (let v of vals) {
this.map.set(v, {
rank: 1,
parent: v,
});
}
}
findParent(v) {
let m = this.map;
let p = m.get(v)['parent'];
if (p === v) return v;
else {
let root = this.findParent(p);
this.map.get(v).parent = root;
console.log(`${v}'s parent is set to ${root}`);
return root;
}
}
isSameSet(v1, v2) {
let root1 = this.findParent(v1);
let root2 = this.findParent(v2);
return root1 === root2;
}
merge(v1, v2) {
let root1 = this.findParent(v1);
let root2 = this.findParent(v2);
if (root1 === root2) return;
let r1 = this.map.get(root1).rank;
let r2 = this.map.get(root2).rank;
if (r1 < r2) {
this.map.get(root1).parent = root2;
console.log(`root is ${root2}`);
} else {
this.map.get(root2).parent = root1;
console.log(`root is ${root1}`);
}
if (r1 === r2) {
this.map.get(root1).rank += 1;
console.log(`rank is set to ${this.map.get(root1).rank}`);
}
}
}
图
DFS深度优先搜索
记忆化DFS搜索
记忆化DFS搜索,就是在DFS搜索的基础上,添加一个哈希表(或数组),用于保存计算过的结果(备忘录)。
当备忘录中存在结果时,直接返回。否则再进行计算+存储。
记忆化搜索是以空间换时间,可以降低时间复杂度。
基本思路:
- 先对原大礼包数组进行筛选,不划算的或礼包中某一物品数量多于所需数量的,都要筛除;
- 搜索从当前需求
need = needs开始,对于每一个need数组,它都对应着一个最低购买价格,我们把求出这个最低价格的函数叫做getMinPrice(),则对于需求need的最低价格为min = getMinPrice(need); - 下面是
getMinPrice()函数的实现:- 最坏情况是,我们的需求,一个大礼包也买不了,这时需要原价买入所有的物品,假设此时价格为
originalPrice; - 对于每一个大礼包,我们现在已知买入它们都是划算的(因为筛选过,但它们划算程度不同)。我们要找到所有大礼包中,买入后能满足当前需求,且总价格最低的;
- 对于每一个大礼包,如果礼包中各物品的数量,都≤当前需求物品数量,则大礼包可以买入。反之,则不能买入。
- 我们遍历所有大礼包,对于一个大礼包
s,它内部物品数目列表为sn,如果它可以买入,那么它买入后,下次我们的需求就变成了need - sn(数组各位分别减去对应物品数目)。那么它买入后需求的最低购入价格就是getMinPrice([need - sn]),因此,买了这个礼包后,我们的购入价格是price_need = getMinPrice([need - sn]) + price_s; - 遍历所有大礼包,对每一个能买入的礼包
s,都计算price_need = getMinPrice([need - sn]) + price_s,则达成当前需求need的最低费用是: 原价购买价格originalPrice与所有price_need中的最小值;
- 最坏情况是,我们的需求,一个大礼包也买不了,这时需要原价买入所有的物品,假设此时价格为
- 每次找到当前need的最低购入价格,就把它放在备忘录
map中,键名是当前need形成的字符串need.join('-'),键值是价格; - 如果当前
need的最低购入价格在备忘录中存在,则直接返回,省去计算步骤; - 要找的结果是最后备忘录中初始需求
needs对应的价格。
BFS广度优先搜索
广度优先搜索从几个节点出发,这些节点本身组成一层。他们可到达的节点组成新的一层,在本层遍历完成后遍历,依次这样分层遍历,直到全部遍历完成。
广度优先搜索一般借助一个队列q来实现,每次从队列头部取出一个元素n,然后把这个元素n的下一层元素添加到队列末尾,这样可以保证元素按序分层遍历。
JS广度优先搜索的优化
因为JS中没有标准的队列数据类型,需要用数组的shift()进行模拟,而数组的shift()是一个比较费时的操作,经常造成TLE。
解决方法是:
每一层用一个next数组存放下一层的结点,将q中的元素一一pop()出来,然后将下一层的元素push()到next数组,最后用next代替q。
这样就避免了shift()操作造成超时。(但是会造成搜索顺序变化)
// template
let q = [init];
while (q.length) {
let next = []; // 新next数组
while (q.length) {
let cur = q.pop(); // 从原队列pop()
let n = cur.next; // 找到下一层结点
next.push(n); // push到next
}
q = next; // 用next代替q
}
拓扑排序
定义
拓扑排序要解决的问题,是给一个有向无环图(DAG:directed acyclic graph)的所有节点进行一维排序,使得对于存在的任何u到v的有向边u -> v, 都可以保证u在v的前面。
实现
拓扑排序的实现,一般有两种形式:Kahn算法 和 DFS。
其区别是:
- Kahn算法:从入度为0的节点开始,正序记录(在入度为0的时候记录数据);
- DFS:在出度为0的时候记录数据,记录顺序为逆序。
Kahn 算法
Kahn算法基本过程:
- 遍历有向无环图,记录每个节点的下一相邻节点集合,以及节点的入度(进入该节点的边数);
- 遍历所有节点,找到初始入度为0的节点,组成初始队列
q; - 每次从队列
q中出列一个节点n,然后执行如下操作:- 将
n添加到结果数组res尾部; - 找到
n全部的相邻下一节点t,将t的入度-1(等同于将n从图中删除); - 如果
t的入度此时为0,则将t加入队列q尾部;
- 将
- 直到队列
q为空,停止遍历,res为拓扑排序结果。
时间复杂度:O(N+E) (N为节点总数、E为边总数)
function kahnSort(g) {
let entryNum = new Map();
let tos = new Map();
for (let [f, t] of g) {
if (!entryNum.has(f)) entryNum.set(f, 0);
if (!entryNum.has(t)) entryNum.set(t, 0);
entryNum.set(t, entryNum.get(t) + 1);
if (!tos.has(f)) tos.set(f, new Set());
tos.get(f).add(t);
}
let q = [];
let res = [];
for (let [k,v] of entryNum.entries()) {
if (v === 0) q.push(k);
}
while (q.length) {
let i = q.shift();
res.push(i);
if (tos.has(i)) {
for (let t of tos.get(i)) {
entryNum.set(t, entryNum.get(t)-1);
if (entryNum.get(t) === 0) q.push(t);
}
}
}
return res;
}
DFS 实现拓扑排序
DFS实现拓扑排序基本过程:
- 用一个数组
visited,标记节点是否被记录; - 遍历图,记录每一节点
n的下一相邻节点集合,集合的元素数目就是n的出度; - 从任意节点开始,遍历全部节点,对任一节点
n,如果其未被遍历:- 如果出度为0,则push
n到结果数组res; - 如果出度不为0,则递归对每一相邻下一节点
t执行dfs(t); - 记录
visited[n]为true;
- 如果出度为0,则push
- 执行完毕,
res为倒序的拓扑遍历结果。
function dfsSort(g) {
let m = new Map(); // 记录下一邻接节点集,以及出度
let nodes = new Set(); // 记录全部节点集合
for (let [f,t] of g) {
if (!m.has(f)) m.set(f, new Set());
m.get(f).add(t);
nodes.add(f);
nodes.add(t);
}
let res = [];
let visited = new Set(); // 已访问节点集合
function dfs(n) {
if (!visited.has(n)) {
visited.add(n);
if (!m.has(n)) {
res.push(n);
return;
}
for (let c of m.get(n)) {
dfs(c);
}
res.push(n);
}
}
for (let i of nodes) {
dfs(i);
}
return res.reverse();
}
特殊的图结构
二分图
一个图的节点能够被分成两组,并且每条边连接的两个顶点,都分别属于不同的组,那么这个图叫做二分图。
另一个等价说法:二分图是一个不包含由奇数条边组成的环的图。
最小生成树
什么是最小生成树
无向连通图的最小生成树(Minimum Spanning Tree,MST),为边权和最小的生成树。
一个由n个节点构成的图,它的最小生成树的边数为n-1。
最小生成树:Kruskal算法
Kruskal算法属于贪心算法。它的流程如下:
- 用并查集维护节点的连通性关系;
- 维护已添加的边的权重加和
sum,以及添加的边数num; - 从所有边中,选出权值最小的边
a -- b,查看a和b是否在同一个连通分量中:- 如果不在,则将这个边的权值计入结果
sum,并将边数num += 1; - 如果在同一个连通分量,则跳过,寻找下一个权值最小边长;
- 如果不在,则将这个边的权值计入结果
- 直到添加了
n-1条边,结束返回。
动态规划(Dynamic Programming)
动态规划是一种思想,将问题分解为一个个状态,利用记忆化的方法储存计算过状态的结果,并利用现有状态结果转移计算新状态的方法。
因此要成功应用动态规划,有几个重要步骤:
- 区分操作和状态:操作是对状态进行转移的动作。首先要区分题目中哪些是可进行的操作,哪些是问题的状态;
- 定义状态:找到问题所描述的解的状态,从而确定定义一个什么样的状态,可以由状态转移逐步推导出问题的解;
- 寻找状态变量:找寻合适的参数变量集合,使得一组确定的参数变量,可以确定问题唯一的状态;
- 给定初始状态或状态的边界: 无法再分割的最小状态,往往对应着单一且显而易见的结果,直接将结果赋值,然后从这些边界状态开始递推;
- 找到状态转移方式: 找到由旧状态递推新状态的方法。
以上都成功应用的话,找到解只是向目标状态进行转移的过程,最终返回解所在的状态结果就可以了。
背包(零钱)问题
背包问题有两种形式:
- ① 0-1背包问题: 背包内的东西只能取一次;
- ② 完全背包问题: 背包内的东西是无限的。
0-1背包问题:
完全背包问题:零钱问题2
0-1背包问题
主要思想是建立一个二维DP数组,行坐标代表物品集合区间,列坐标代表背包的剩余容量。
dp[r][c]的含义是: 背包剩余容量为c的情况下,仅由[0,r]中的物品组成,能装下的最大价值。
这样对于一个[r,c]组合,有两种选择:
- 选择装下这个物品r:假设物品r本身重量为wr,价值为vr,那么背包剩余容量为c-wr,物品r已经装入,只能从
[0,r-1]物品区间继续装入,此时能装下的最大价值为dp[r-1][c-wr]。 因此这种情况的最大价值为vr+dp[r-1][c-wr]; - 放弃装这个物品r:最大价值与r-1个物品时一样。为
dp[r-1][c]。
每次选二者之中较大者。
因为每次值只用到了r-1和r两行数据,可以对dp数组进行压缩。
最大可以压缩为一行。每次需要从右到左更新数据。(见上面的详解最下方。)
完全背包问题
0-1背包问题中,每个物品只能选择一次。而完全背包问题中,每个物品的数目是无限的,可以重复选择。
经典完全背包问题:凑零钱。给出零钱种类和目标值,求组成目标值的方法数。(比如由1,2,5组成10元有几种方法)
对于完全背包问题,存在一个for循环先后顺序导致的,排列数和组合数的问题。
详细说明:
动态规划解题,可以想到将钱数amount和钞票面值note联系起来: 组成一个目标值amount的方法数,等于所有钞票面值note对应的amount-note的方法数加在一起。
dp[amount] = sum( dp[amount-note] )比如: 如果给出钞票
[3,10],那么组成目标钱数20的方法数,应该等于组成20-3=17和20-10=10的方法数之和。因为组成17的每一个方法,再加上一张3元的钞票,就都可以组成目标值20,另一个例子同理。可以用两层for循环分别遍历amount数组和notes数组,动态更新amount数组的值:
amount[i] += amount[i-note]。但是这里存在一个遍历顺序问题:
① 如果先遍历amount,后遍历notes,则意味着:对于每个目标值,都直接穷举出所有当前可能的钞票组合,之后再进入下一个目标值进行更新。
② 如果先遍历notes,后遍历amount,则意味着:对于每个钞票note,先计算并更新单独由这个note组成各个目标值的方法数,然后再进入下一个面额note,再更新这个新面额和之前所有面额组成的方法数,保证了每个方案中的钱的排布顺序,是
notes的顺序。对于情况①,计算出来的是所有的无重复排列数。对于情况②,计算出来的是无重复组合数。
本题不同排列同一组合,视为同一个方法,因此应该使用第二个遍历方式。
股票买卖
给你一个每日股票价格组成的数组prices(索引是日期,值是价格),和一个可交易次数k。编写返回可实现的最大收益的函数。
股票同时期最多只能持有一份,一次也只能交易一份。也就是如果持有,必须先卖出才能再买入。
思路分析:
- 一天可以有三种选择:买入、卖出、不操作;
- 只有卖出才能获得收益;
- 卖出必须先买入;
- 如果不操作,则总收益和之前一天的收益相同。
基于以上四点,可以得出下面的算法:
对于某一天,只关注卖出操作。我们可以选择卖出或不卖出。
- 如果卖出, 则之前必定有一天进行了买入。此次交易赚取收益为
price[sell]-price[buy];- 如果不卖出,则总收益与前一天收益相同;
设置一个矩阵,每一行代表最大可交易次数k,每一列代表交易日期day。每一个元素代表最大交易次数为k时,当前日期所能达到的最大收益。
则有如下关系:

function maxProfitWithKTransactions(prices, k) {
if(prices.length < 2) return 0;
let dp = new Array(2);
dp[0] = new Array(prices.length) .fill(0);
dp[1] = new Array(prices.length);
let trans = 1;
while(trans <= k){
for(let i=0; i<prices.length; i++){
if(i === 0) dp[1][i] = 0;
else {
let notSellMaxProfit = dp[1][i-1];
let sellMaxProfit = -Infinity;
for(let buyDay=i-1; buyDay>=0; buyDay--){
sellMaxProfit = Math.max(sellMaxProfit, prices[i]-prices[buyDay]+dp[0][buyDay]);
}
dp[1][i] = Math.max(notSellMaxProfit, sellMaxProfit);
}
}
dp[0] = dp[1];
dp[1] = new Array(prices.length);
trans++;
}
return dp[0][prices.length-1];
}
三个无重叠子数组最大和
使用动态规划方法解题。步骤如下:
- 先遍历数组,用一个map记录以i位置为结束位置的长度为k的子数组的加和,i<k-1的值都为0,因为元素数目不够。(map.get(i)是
[i-k+1, i]区间的加和); - 使用一个二维dp数组保存计算结果。
- dp的行n取值从0到3,代表可以选取的不相交子数组个数;
- dp的列i取值从0到nums.length-1,代表结束位置;
- 因此,
dp[n][i]代表可以取n个子数组时,[0,i]区间内可以取到的n个子数组的最大和。
- 当n=0时,
dp[n][i]全部为0;其他情况下,当进行dp[n][i]的取值时,分为以下两种情况:- 不使用当前位置i构成的子数组map.get(i):
dp[n][i] = dp[n][i-1] - 使用当前位置i构成的子数组map.get(i): 则子数组
[i-k+1,i]一定被使用了,当前dp值应该为dp[n][i] = dp[n-1][i-k] + map.get(i)
- 不使用当前位置i构成的子数组map.get(i):
- 当n=3,保留结果中的最大值和它对应的索引值index;
- 反向查找dp表,获得各子数组起始索引:
- 对于一个值
dp[n][i],如果它使用了i位置的子数组,那么dp[n][i]一定大于dp[n][i-1]; - 从n=3开始找,一直到n=1,保存结果值返回即可。
- 对于一个值
var maxSumOfThreeSubarrays = function(nums, k) {
let map = new Map();
let first = 0;
for(let i=0; i<k; i++){
first += nums[i];
map.set(i,0);
}
map.set(k-1, first);
for(let i=k; i<nums.length; i++){
let cur = nums[i];
let prev = nums[i-k];
let sum = map.get(i-1) + cur - prev;
map.set(i, sum);
}
let dp = new Array(4).fill(0).map(i => new Array(nums.length).fill(0));
let max = -Infinity;
let index = 0;
for(let n=1; n<4; n++){
for(let i=0; i<nums.length; i++){
let notUsed = i-1 >= 0 ? dp[n][i-1] : 0;
let used = i-k >= 0 ? map.get(i) + dp[n-1][i-k] : map.get(i);
dp[n][i] = Math.max(notUsed, used);
if(n === 3 && dp[n][i] > max){
max = dp[n][i];
index = i;
}
}
}
function findIndex(i){
let n = 3;
let res = [0,0,0];
while(n > 0){
while(i >= 0 && dp[n][i] === dp[n][i-1]){
i--;
}
res[n-1] = i-k+1;
i = i-k;
n--;
}
return res;
}
return findIndex(index);
};
最长回文子序列
思路:
- 回文序列首尾元素一定相同;
- 设置一个二维dp数组,
dp[i][j]代表从[i,j]区间的最长子序列长度; dp[i][j]递推根据首尾元素是否相同判断:- 如果首尾元素相同,则
dp[i][j] = dp[i+1][j-1] + 2; - 如果首尾元素不同,则它们必定不能同时作为最长子序列的首尾,
dp[i][j] = max (dp[i+1][j], dp[i][j-1])。
- 如果首尾元素相同,则
- 需要注意dp遍历顺序问题,如果j从0到字符串末尾,那么i需要从j-1递减到0,这样才能正确利用之前的计算结果。
从1到n的BST的种类数
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
思路:
- 对于一个数字
n,那么从1到n,每一个数都可以选取作为根节点; - 根据BST的性质,如果选择了i作为根节点,那么:
[1,i-1]的元素都在左子树;[i+1,n]的元素都在右子树。
- 根据BST的规则,
[1,n]的BST种类和[1+K,n+K]的BST种类相同; - 设
dp[i]为[1,i]区间可构建的BST种类数,那么:[1,i-1]的元素都在左子树,构建的BST种类数为dp[i-1];[i+1,n]的元素都在右子树,构建的BST种类数为dp[n-i]。
- 对于一个根节点,总种类数为左右子树种类数相乘,则有状态转移方程:
dp[i] = dp[i-1] * dp[n-i]; - 从1到n遍历
n,对每一个n遍历i = [1,n]选取作为根节点,计算其种类数加和做为dp[n]; - 返回
dp[n]即可。
区间DP
状态与区间相关,且可以由区间的切分等进行状态转移。
区间DP的基本流程是:
dp[l][r]代表闭区间[l,r]范围内的结果;- 对
[l,r]区间进行某种拆分,常见的是在[l+1,r-1]区间枚举切分点i,将区间分为[l,i]和[i,r]两部分,并对每个切分点结果进行比较取最值,记录到dp[l][r]; - 注意区间DP的顺序问题:因为大区间要用到小区间的信息,所以遍历的时候要先以区间长度
len为条件(从小到大),再枚举区间的起点l(从小到大、从大到小均可),r的位置此时可以确定为l+len;
- 假设
dp[l][r]为[l,r]区间切分的最小得分,那么整体的最小得分就是dp[0][len-1]; - 在
[l+1,r-1]区间内可以枚举切分点,将区间分为[l,i]和[i,r]两部分; dp[l][r] = min(dp[l][i] + dp[i][r] + v[l]*v[r]*v[i]);
var minScoreTriangulation = function(values) {
// 区间DP
// dp[l][r]: [l,r] 区间的最低分。
// dp[l][r] = min(v[l]*v[r]*v[k] + dp[l][k] + dp[k][r]), k -> [l+1, r-1];
let dp = new Array(values.length).fill(0).map(i => new Array(values.length).fill(Infinity));
for (let len = 1; len <= values.length-1; len += 1) {
for (let l=0; l+len<values.length; l++) {
if (len === 1) {
dp[l][l+len] = 0;
continue;
}
for (let i=l+1; i<=l+len-1; i++) {
dp[l][l+len] = Math.min(dp[l][l+len], values[l]*values[l+len]*values[i] + dp[l][i] + dp[i][l+len]);
}
}
}
return dp[0][values.length-1];
};
贪心算法
分治算法
平面最近点对
给出一系列二维平面内的点
[p1,p2,p3,p4...],每个点由[x,y]坐标构成,请寻找最近的一对坐标点之间的欧氏距离。
思路
- 直接暴力求解,问题复杂度为
O(n^2),复杂度高的原因是进行了大量的无意义计算(比如相隔非常远的点间距离); - 可以用一条线将平面分割成两部分(假定选择垂直于X轴的竖线),发现问题可以被分为子问题:
- 左边部分点集的最小距离
l_min; - 右边部分点集的最小距离
r_min; - 横跨左右点集的最小距离
m_min;
- 左边部分点集的最小距离
- 对于任何一个点集的最终结果,都是上述三个子区间各自结果中的最小值
min(l_min, r_min, m_min); - 采用分治算法:
- 先对点集进行按x坐标从小到大排序;
- 递归出口:如果区间内的元素小于
3个,直接进行计算返回; - 按上述划分法,对每一个区间
[l,r],取中间点m = Math.floor((l+r)/2);,分割成左右两部分; - 对左右两部分分别递归求最小距离,假设结果为
l_min和r_min,我们取它们二者中的最小值为delta; - 对
m位置的左右两侧,只对± delta范围内的元素进行求距离比对,找出这个范围内的最小距离m_min; - 返回三者中的最小值。
实现
function getDist(p1, p2) {
return Math.sqrt((p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2);
}
function closestPair(points, l = 0, r = points.length - 1) {
if (r - l <= 2) {
if (r - l === 1) return getDist(points[r], points[l]);
let a = getDist(points[l], points[l + 1]);
let b = getDist(points[l + 1], points[r]);
let c = getDist(points[l], points[r]);
return Math.min(a, b, c);
}
let m = Math.floor((l + r) / 2);
let lmin = closestPair(points, l, m);
let rmin = closestPair(points, m+1, r);
let delta = Math.min(lmin, rmin);
// +- delta
let leftSet = new Set();
let rightSet = new Set();
let c = m;
while (c >= 0 && Math.abs(points[c][0] - points[m][0]) <= delta) {
leftSet.add(points[c]);
c -= 1;
}
c = m + 1;
while (c < points.length && Math.abs(points[c][0] - points[m][0]) <= delta) {
rightSet.add(points[c]);
c += 1;
}
for (let p1 of leftSet) {
for (let p2 of rightSet) {
lmin = Math.min(lmin, getDist(p1, p2));
}
}
return Math.min(lmin, rmin);
}
// test
let p = [[1,2],[2,1],[3,200]];
p.sort((a,b) => a[0] - b[0]);
console.log(closestPair(p)); // 1.414..
为运算表达式设计优先级
采用分治算法+dfs:
- 设置一个dfs(l,r)函数,用来计算原表达式从l到r闭区间内子表达式的计算结果;
- 原表达式可以从任一操作符一分为二,可知左右两侧仍是一个表达式;
- 对两侧表达式重复上述分割步骤,直到两侧为不含操作符的数字;
- 每一个表达式因计算优先级的不同,可能有多种计算结果,因此返回的应该是一个数组,里面保存了所有表达式可能的计算结果;
- 每次用当前运算符,对左右两个表达式的计算结果进行遍历计算,合并结果集,最终返回整个表达式的结果。
var diffWaysToCompute = function(expression) {
// 测试字符串是否是纯数字
function isNumber(str) {
return /^\d+$/i.test(str);
}
// 执行单次计算
function cal(l, r, o) {
switch (o) {
case '+': {
return l+r;
}
case '-': {
return l-r;
}
case '*': {
return l*r;
}
}
}
// 按操作符分隔表达式,取结果集合。
function dfs(l = 0, r = expression.length-1) {
if (isNumber(expression.slice(l,r+1))) {
return [+expression.slice(l,r+1)];
}
let res = [];
for (let i=l; i<=r; i++) {
if (!isNumber(expression[i])) {
let left = dfs(l, i-1);
let right = dfs(i+1, r);
let operater = expression[i];
for (let i of left) {
for (let j of right) {
res.push(cal(i, j, operater));
}
}
}
}
return res;
}
return dfs();
};
回溯算法
算法基本思路
回溯算法是遍历决策树的过程。决策过程可以表示为当前路径、当前决策空间和结束条件。
- 当前路径:是由已经进行过的所有决策组成的。下一步决策依赖于当前走过的决策路径。(比如:有三张牌ABC,第一次选择B,第二次选择C,则当前第三次选择的路径为B-C);
- 当前决策空间:根据当前路径,本次决策剩余的选择空间。(ABC三张牌,前两次选择BC,则第三次当前选择空间只有一张牌A);
- 结束条件:决策空间中没有任何选项时,则代表决策树遍历到尽头,需要用结束条件处理这次决策的结果。(比如将当前决策路径B-C-A保存起来)
回溯算法一般是基于递归调用实现,递归主要负责实现决策树的遍历。回溯算法的主要过程如下:
- 先判断当前路径是否满足结束条件,满足则执行结束操作;
- 在当前决策空间B内进行决策,然后在当前路径A中添加当前决策(结果为A1),在当前决策空间B中去掉当前决策(结果为B1);
- 以A1为下一决策的路径,以B1为下一决策的决策空间,递归调用自身;
- 调用完成后,将决策路径B1恢复为B,路径A1也恢复为A。(这一步称为回溯过程)
回溯算法的应用:DFS深度优先搜索、全排列问题、组合问题等。
注意:
理论上使用回溯算法,执行决策后的回溯过程(恢复空间),应该与决策前的顺序正好相反,代码在结构上完全镜像对称。否则容易出现Bug。
回溯的注意事项
- 回溯算法复杂度高(
O(n!)),一般数据量要小于20; - 回溯算法本质上是递归,一般都可以应用记忆化方法,记录计算结果,防止重复计算;
- 回溯计算过程中,如果找到了想要的结果,要及时提前退出递归,终止后续计算。
回溯算法:全排列问题
元素互不相同的全排列
给定一个由字母组成的数组arr,数组中元素互不相同,请返回由全部数组元素组成的所有排列。
例如:
['a','b','c']的全排列是[['a','b','c'],['a','c','b'],['b','a','c'],['b','c','a'],['c','b','a'],['c','a','b']]
考虑使用回溯算法:
- 当前路径就是已经选择过的字母序列,当前决策空间就是剩余的可被选择的字母集合;
- 每次决策,在剩余字母中选择一个(比如’a’),添加到路径中,然后在可选择字母集合中删除掉这个已经选过的字母a;
- 使用新路径和新决策空间,递归调用执行下一次决策;
- 结束条件:当可选择字母集合为空,说明排列已经完成,将结果添加到结果集合,然后返回;
- 递归调用完成后,恢复路径(删掉添加的字母a)和决策空间(恢复字母a)。
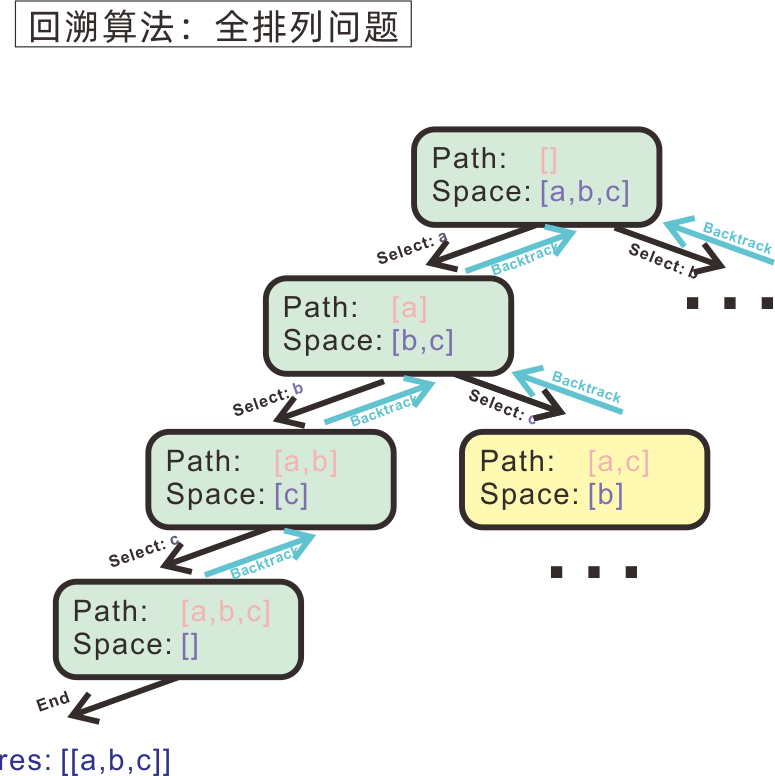
代码如下:
// 方法1:
function getArrangement(arr, path=[], res=[]){
// arr是当前决策空间,path是当前路径
// 1.判断结束条件:决策空间内无元素可选;
if(arr.length === 0){
res.push(path.slice());
return;
}
for(let i=0; i<arr.length; i++){
// 2.进行决策;
let selected = arr[i];
// 3. 修改决策空间和路径,用来进行下一次决策;
path.push(selected);
arr.splice(i, 1);
// 4. 递归调用,执行下一次决策;
getArrangement(arr, path, res);
// 5. 恢复 决策空间 和 路径。
arr.splice(i, 0, selected);
path.pop();
}
return res;
}
// 方法2: 使用一个used记录选择的路径
function allArrangement2(arr){
let path = [], used = new Array(arr.length).fill(false);
let res = [];
function backtrack(){
if(path.length === arr.length){
res.push(path.slice());
return;
}
for(let i=0; i<arr.length; i++) {
if (!used[i]) {
path.push(arr[i]);
used[i] = true;
backtrack();
used[i] = false;
path.pop();
}
}
}
backtrack();
return res;
}
元素存在重复的全排列
当给定数组中存在重复元素时,进行全排列会出现重复结果。
比如: [1,1,2,3]的全排列中,[1,1,2,3]本身会出现两次,因为存在两个1。
解决方法是:在相同决策空间进行选择的时候,进行一个判断。如果前后两次选择的元素值相同,则后续排列必重复,直接跳过此次选择即可。
例如在某次决策过程中,决策空间为
[1,1,2,3],选择从左到右进行。本轮选择为第一个1元素,则下一次决策的空间为[1,2,3]。本轮回溯过程执行完毕后,下次决策选择了第二个元素,此时发现同样为1元素,剩余空间还是
[1,2,3]。那么这两次决策结果一定相互重复,第二轮直接跳过即可。
function backtrack(path=[], space=nums, res=[]){
if(space.length === 0){
res.push(path.slice());
return;
}
// 为每一轮回溯决策过程,设置一个Set,用来保存已经选择过的元素值。
let set = new Set();
for(let i=0; i<space.length; i++){
// 当该决策空间中已经选取过当前元素,直接跳过,防止重复。
if(set.has(space[i])) continue;
else {
set.add(space[i]);
let cur = space[i];
path.push(cur);
space.splice(i,1);
backtrack(path, space, res);
space.splice(i,0,cur);
path.pop();
}
}
return res;
}
全部子集(组合问题)
求子集的回溯算法,思路如下:
- 设置一个path,代表已经选择的元素路径;
- 对于每一个path,设置一个start值,代表下次选择的起始位置;(含义是:path条件下,
index < start的全部元素子集已经处理完毕) - 每次从start到数组结尾遍历剩余选择空间,将元素放入path然后记录到结果数组,最后返回结果数组。
子集(组合)问题,每次都要进行判断,记录结果,而不是在最后判断返回。
function allCombination(arr){
function backtrack(path = [], start = 0, res = []){
// 对于每一个path,选择空间是[start, arr.length-1],[0,start) 全部子集都处理完成,不用考虑。
for(let i=start; i<arr.length; i++){
path.push(arr[i]); // 对于每一个可选择元素,我们可以将其加入组合,也可以选择跳过(不加入)。
res.push(path.slice());
backtrack(path, i+1, res);
path.pop(); // 回溯,当前元素arr[i]被选择的情况已经遍历完成,将其弹出(表示当前元素被跳过),继续下一个元素的决策。
}
return res;
}
return backtrack();
}
组合的去重
如果一个集合arr中有重复的元素,那么在上述求组合的结果中,会出现重复的组合。
重复组合: 组合中的元素种类,及各种类的数目都相同。
例如:
[1,2,3]和[3,2,1]
去除重复组合的方法:
- 先将数组排序,这样重复的元素位置会相邻分布;
- 在回溯寻找组合的过程中,对于某次元素选择
arr[i],查看其上一元素arr[i-1]是否与它相同,如果相同则跳过。
var subsetsWithDup = function(nums) {
nums.sort((a,b) => a-b); // 先排序,让相同元素凑在一起。
function backtrack(path = [], start = 0, res = []){
for(let i=start; i<nums.length; i++){
if (i > start && nums[i] === nums[i-1]) continue; // 这里判断当前元素与前一元素是否相同,相同则跳过。(同一深度,添加相同的元素会造成重复)
path.push(nums[i]);
res.push(path.slice());
backtrack(path, i+1, res);
path.pop();
}
return res;
}
return backtrack();
};
回溯算法:括号匹配
回溯算法,解法等同于div标签生成.
var generateParenthesis = function(n) {
function backtrack(path=[], leftleft=n, rightleft=n, res=[]){
// 结束条件
if(leftleft === 0 && rightleft === 0){
res.push(path.join(''));
return;
}
// 回溯:选择
if(leftleft > 0){
path.push('(');
backtrack(path, leftleft-1, rightleft, res);
path.pop();
}
// 这里可以保证:右括号只有在有左括号能匹配的情况下,才会被添加。
if(rightleft > leftleft){
path.push(')');
backtrack(path, leftleft, rightleft-1, res);
path.pop();
}
return res;
}
return backtrack();
};
回溯算法:优美的排列
回溯算法的路径,如果每次选择只涉及两种情况,则可以使用一个与原空间等长度的数组,用true和false代表选择的与否。
递归
递归的特点和基本思想
递归是一种解空间的遍历手段,它不同于for/while循环,递归遍历的空间可以是非线性的。(图、树等)
递归通过在函数内调用自身实现。递归在内存中是通过函数调用栈来实现的,每次调用函数在调用栈中压入函数,函数执行完毕后弹出,恢复上层函数的执行环境。
因为这个原因,递归在内存中需要占用空间,空间复杂度较高。(占用空间与函数的最大调用次数n正相关。)
递归的注意事项:
- 设置合理的退出条件;
- 递归深度影响空间复杂度,能用迭代实现尽量不用递归。
递归复杂度分析
递归问题的复杂度可以画递归树分析:
时间复杂度等于:每次函数调用的时间复杂度 × 递归调用次数。
空间复杂度等于:每次调用函数所需空间复杂度 * 最大递归深度。
典型递归问题
思路: 回溯算法,递归实现。
- 控制可用的开始和结束标签数目,当开始标签可用数>0时,向后面添加一个开始标签;
- 然后检查结束标签可用数,如果发现结束标签可用数大于开始标签可用数,说明有开始标签没有被正确关闭,此时向字符串后添加一个结束标签;
- 当开始标签和结束标签可用数都为0,则向结果数组中保存结果。
function generateDivTags(numberOfTags) {
let res = [];
function getStrings(prefix, openings, closings, result){
if(openings === 0 && closings === 0){
result.push(prefix);
}
if(openings > 0){
let newPrefix = prefix + '<div>';
getStrings(newPrefix, openings-1, closings, result);
}
if(closings > openings){
let newPrefix = prefix + '</div>';
getStrings(newPrefix, openings, closings-1, result);
}
}
getStrings('', numberOfTags, numberOfTags, res);
return res;
}
排序算法
堆排序
构建堆(也叫优先级队列)
适用于:在对一个集合的遍历过程中,动态获取最大值或最小值的问题。
例如: 获取一个数组中出现次数最高的前N个元素。
为集合元素构建堆(大顶堆、小顶堆),可以通过堆排序,方便获取某一属性优先的前N个元素。
字典序
字典序的比较优先级从高到低(以字典序从小到大为例):
- 从前到后逐位比较,同一位置上字符值更大的,字典序更靠后;
- 前缀相同的两个字符串,长度更长的,字典序靠后;
也就是说,在字典序中比较两个字符串a和b,相当于比较它们最靠前的不同字符a[i]和b[i]。
一个给定的字典序排列[a,b,c,d,e...],假设长度为n,则:
- 它可以按照给定的字母顺序,形成一个
n叉字典树; - 将字符串按字典序排列,等同于将字符串加入这个字典树,然后对这个
n叉树进行先序遍历。
搜索算法
各种搜索问题,本质上都是树的遍历问题。
二分查找
复杂度分析
时间复杂度: O(logN),N为原数组长度。
空间复杂度: O(1)
二分查找适用情况
应用二分查找的必要条件是:
- ①顺序存储:数组结构;
- ②有序,可以缩小结果范围。
一般适用于:按序排列的数组元素搜索。
二分查找的关键信息
- 成功应用二分查找,必须要找到一个根据中间点,能对左右两侧区间进行取舍的判据;
- 二分查找的最终时间复杂度为
O(log_n);
★二分查找的区间情况和对应的代码
假设二分查找应用的数据是升序排列的,假设它的区间是[a,b]。将它以目标值target分成两部分,一定是如下两种情况之一:
[a,target)和[target,b];[a,target]和(target,b]。
对于一个target,我们进行查找的目标的情况可以是:
≤target的最后一个元素;<target的最后一个元素;≥target的第一个元素;>target的第一个元素。
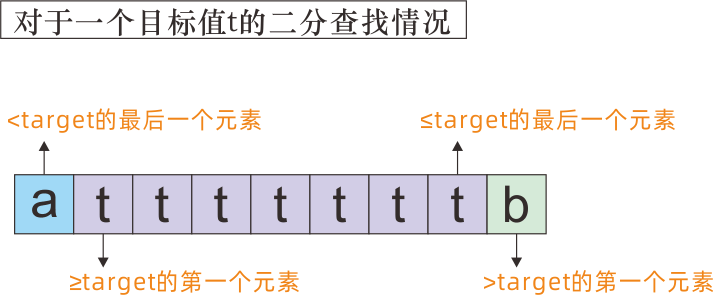
需要根据上述四种查找的目标情况,对区间进行正确切分,注意我们需要保证[left,right]区间内元素是我们想要的元素,而且最后left和right要重合,否则会出现数组越界。
- 查找
≤target的最后一个元素时:- mid ≤ target: left = mid;
- mid > target: right = mid - 1;
- mid的取整情况:向上取整。
- 查找
<target的最后一个元素:- mid < target: left = mid;
- mid ≥ target: right = mid - 1;
- mid的取整情况:向上取整。
- 查找
≥target的第一个元素:- mid < target: left = mid + 1;
- mid ≥ target: right = mid;
- mid的取整情况:向下取整。
- 查找
>target的第一个元素:- mid ≤ target: left = mid + 1;
- mid > target: right = mid;
- mid的取整情况:向下取整。
这里有几个技巧(对于升序排列):
- 先正确切分区间(哪边闭哪边开),然后判断查找的目标区间在哪一侧,目标区间边界在收缩的时候一定是闭的(在左侧:
left = mid或 在右侧:right = mid); - right只能向左缩小,left只能向右缩小。也就是说,left、right取值只有以下两种情况:
- left = mid, right = mid - 1;
- left = mid+1, right = mid;
- 向上还是向下取整,取决于哪边是开区间:
- 当存在left = mid + 1,向下取整;
- 当存在right = mid - 1, 向上取整。
- 二分查找过程中,mid的判断条件,和区间的切分情况一定完全相同。需要做的只是根据区间的切分情况,对mid进行开闭取舍;
- mid位于目标值target左侧,动左区间。mid位于目标值右侧,动右区间。
此外,二分查找的取中点操作,一定要用
Math.floor((l+r)/2)形式,而不是位运算(l+r) >> 1!因为JS对位运算参与的数,当做32位整数处理,而不是64位。这样做在数值大于
2^32-1的时候会造成计算错误。Math.floor(((2 ** 31) - 1)/2) // 1073741823 ((2 ** 31) - 1) >> 1 // 1073741823 Math.floor(((2 ** 32) - 1)/2) // 2147483647 ((2 ** 32) - 1) >> 1 // -1
基本代码实现
二分查找实现的两种方式:1.迭代 2.递归。
// 递归实现:升序数组nums中,查找≤target的最后一个元素。
const search = function(nums,target) {
function find(left, right){
if(left < right){
let mid = Math.ceil((left+right)/2);
if(nums[mid] <= target) return find(mid, right);
else return find(left, mid-1);
}
return left;
}
return find(0,nums.length-1);
};
// 迭代实现
var search = function(nums,target) {
let left = 0, right = nums.length-1;
while(left < right){
let mid = Math.ceil((left+right)/2);
if(nums[mid] <= target) left = mid;
else right = mid-1;
}
return left;
};
二(多)维空间的二分查找
对于一个二(多)维数组,如果它的元素按照各维度的增长方向,已经是有序排列,那么它就满足了二分查找的条件:可以对任意一个中间值mid,查找比mid大或小的元素个数。
方法如下:
- 先确定元素的左右极值:因为为有序排列,极值位于维度增长方向的两个端点;
例如:
对于二维数组
arr,如果按行按列都是递增的,那么极小值在arr[0][0],极大值在arr[arr.length-1][arr[0].length-1],也就是左上角、右下角; - 对于一个
k维有序数组,我们可以在O(nk-1)时间复杂度完成一次查询,方法是:固定其他维度,将多维降为二维,然后找到二维数据某一递增轴的末端点,作为起点,向另一个轴方向进行计数;
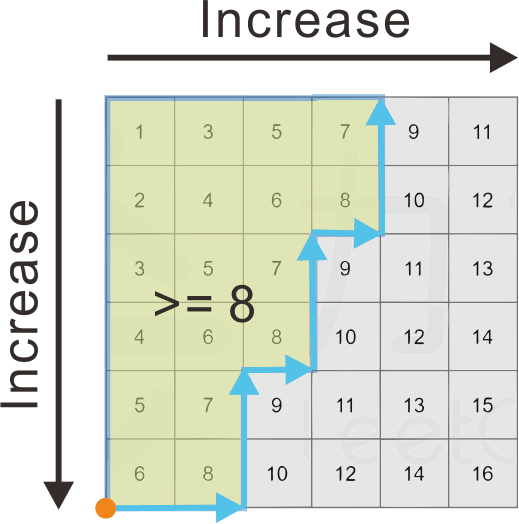
- 然后利用左右极值,进行常规二分查找即可。
滑动窗口
适用于:在一个大的连续空间,寻找满足特定要求的连续子区间。
滑动窗口中用到了左右两个指针,它们移动的思路是:以右指针作为驱动,拖着左指针向前走。右指针每次只移动一步,而左指针在内部 while 循环中每次可能移动多步。右指针是主动前移,探索未知的新区域;左指针是被迫移动,负责寻找满足题意的区间。
— 《挑战程序设计竞赛》
滑动窗口的基本过程是:
- 通过左右边界维护一个窗口:
left和right,初始都在0位置; - 窗口的有效区间范围是
[left, right]双闭区间; - 右边界是主动前进的,它负责向右扩展窗口探索新区域,每次只前进一步;
- 左边界是被动前进的,因为每次右边界都会前进,窗口内的值可能不再符合要求,需要收缩左边界使得当前窗口内的值继续满足要求,左边界每次可以前进多步;
- 直到右边界到达末尾
length-1位置,停止搜索。
// 滑动窗口的伪代码
let left = 0, right = 0;
let target = 0, res = 0;
while (right < arr.length) {
target += arr[right];
while (/* target do not fit the condition */) {
target -= arr[left]; // decrease length of the window, change the target value.
left += 1;
}
res = target // record the found answer here.
right += 1;
}
return res;
枚举
当问题解的空间不大时(一般小于 2^16),可以直接进行枚举,找出所有的解。
特殊情况下,可以用二进制数字表示每个状态,通过二进制数字进行解空间的枚举。
双指针
快慢指针
快慢指针:同一方向,不同前进速度的两个指针。
快慢指针的用途:
- 链表寻环: 使用快慢指针,快指针比慢指针每次多走1步,如果有环存在,则快慢指针一定会相遇;
- 寻找链表的中点; 使用快慢指针,慢指针每次走1步,快指针每次走2步,则快指针到达尾部,慢指针正好在链表中间位置;
有序集合
跳表 SkipList
跳表是有序链表的扩展,是有序集合的一种。它可以实现O(logN)时间复杂度的集合元素添加、删除和查询操作。
相比于各种平衡树,跳表的平均时间复杂度相当,且在原理和实现上更为简单。
跳表为什么能够降低有序链表查询的时间复杂度?
跳表为有序链表的每个结点,额外增加了多个指针,用于指向其他节点。这些指针被分成多层,层数从低到高,每层的指针数目递减。查询时,从最顶层开始查找,这样可以大步长快速定位到查询节点附近,然后逐层降低层数,直到层数为0,返回查询到的结果(或未找到)。
因为跳表涉及到频繁插入、删除等操作,无法使用固定的递减模式进行层数设计。跳表一般使用一个概率值p确定节点指针的层数,并设置一个最大层数M,防止层数过高。
根据Redis的实现,M = 32, p = 1/4是合适的。
// Marswiz @2022
// Skiplist in JS.
class SkipList {
MAX_LAYER = 32;
P = 1 / 4;
constructor(data = []) {
this.tail = new Node(Infinity, new Array(this.MAX_LAYER).fill(0).map(i => null));
this.head = new Node(-Infinity, new Array(this.MAX_LAYER).fill(0).map(i => this.tail));
for (let i of data) {
this.addNode(i);
}
}
addNode(val) {
let p = this.P;
let nextLayer = [null];
while (nextLayer.length < this.MAX_LAYER && Math.random() <= p) nextLayer.push(null);
let curNode = new Node(val, nextLayer);
let curLayer = this.MAX_LAYER - 1;
let cur = this.head;
while (curLayer >= 0) {
while (this.getNext(cur, curLayer).val <= val) {
cur = this.getNext(cur, curLayer);
}
if (curLayer < nextLayer.length) {
curNode.next[curLayer] = cur.next[curLayer];
cur.next[curLayer] = curNode;
}
curLayer -= 1;
}
}
getNext(node, layer) {
return node.next[layer];
}
show() {
let cur = this.head;
let res = [];
while (cur !== null) {
res.push(cur.val);
cur = cur.next;
}
console.log(res);
}
}
class Node {
constructor(val = 0, next = [null]) {
this.val = val;
this.next = next;
}
}
一些操作
概念定义
子序列: 由原数组中部分或全部元素组成的新数组,子序列中元素的先后顺序必须与原数组相同,但是元素在原数组中不必相邻。
子数组: 由原数组中部分或全部元素组成的新数组,子数组中元素的先后顺序必须与原数组相同,而且元素在原数组中必须相邻。
字符串操作
- 字母转化为数值:
a.charCodeAt(0) - 97; (97是字母a的ASCII码)
位运算
- 补码:
- 正数的补码是它本身;
- 负数的补码,是符号位保持为
1不变,其他位取反,然后整体再加1。
AND OR XOR都满足交换律和结合律;(a&b)^(a&c) = a&(b^c)x^0 = xx^x = 0>>是带符号右移,表示移动过程中左侧空出来位置用符号位的值来填充(正数补0,负数补1);>>>是无符号右移,表示移动过程中左侧空出来位置,始终用0来填充;a & (-a)可以找出数字a的最低非0位;
BigInt
- 除了比较数值大小外(
>/</>=/<=),BigInt只能与BigInt类型进行计算; - BigInt基本可以表示任意长度的整数,但仍有上界,只是非常大;
- BigInt的位运算:
- BigInt只有带符号左右移操作符
<<和>>; - BigInt在
<<和>>的时候,不会被视作32位整数,而是它本身。
- BigInt只有带符号左右移操作符
因此
1 << 32和1n << 32n结果是不同的,1n << 32n会返回正确的结果。
数组操作
数组中随机取一个元素
let randPos = Math.floor( Math.random() * arr.length )
let res = arr[randPos]
数组中删除一个元素
arr.splice(position, 1)
数组中动态删除元素,考虑从右到左遍历
从右到左遍历,指针左侧的元素不会被动态修改,指针右侧的元素删除不影响指针的下一位置。
浅拷贝数组
// 1.
Array.from(arr);
// 2.
arr.slice();
// 3.
[].concat(arr);
数组sort排序
// 字符串升序
arr.sort()
// 字符串降序
arr.sort().reverse()
// 数字升序
arr.sort( (a,b) => a-b )
// 数字降序
arr.sort( (a,b) => b-a )
判断变量类型
// 精确返回变量类型,首字母大写
Object.prototype.toString.call(arg).slice(8,-1)
链表操作
链表的前序、后序遍历
function iterate(nodeHead){
if (nodeHead) {
// 这里写是前序;
iterate(nodeHead.next);
// 这里写是后序。
}
}
数值操作
辗转相除找最大公约数
function gcd(num1, num2) {
return num2 === 0 ? num1 : gcd(num2, num1 % num2);
}
找两数最小公倍数
let LCM = num1 * num2 / gcd(num1,num2);
寻找1 ~ n范围内每个数的约数
这个算法的复杂度为O(n * log_n)。
因为内层循环执行了n/1 + n/2 + ... + 1次,其级数的极限为log_n。而外层循环执行n次,所以总时间复杂度为O(n * log_n)。
function findDividers(n) {
let res = new Array(n+1).fill(0).map(i => new Array(0));
for (let i=1; i<=n; i++) {
for (let j=i; j<=n; j+=i){
res[j].push(i);
}
}
}
ABC集合的合集元素数目
|A∪B∪C| = |A| + |B| + |C| - |A∩B| - |A∩C| - |B∩C| + |A∩B∩C|
合并区间
对于一系列闭区间组成的数组arr:[[l1,r1],[l2,r2],[l3,r3]...[ln,rn]],它们之间可能无序,也可能存在嵌套,合并它们的策略是:
- 先按起始位置
l1,l2,l2.3...对区间进行升序排序; - 声明一个left和一个right变量,用来保存当前区间的左右边界值,以及一个数组res用来保存结果;
- 从左到右遍历区间数组(索引index从0到n-1),对每个区间
[l1,r1]和它下一个区间[l2,r2],因为排过序可知此时存在l2 >= l1:- 如果l2 > r1,说明下一个区间和现在的区间不重合,直接把现在的结果区间
[left,right]放入结果数组,并更新left = l2, right = r2; - 否则l2 <= r1,说明区间存在重合:
- 此时如果r2 <= r1,说明
[l2,r2]区间被完全覆盖,此时直接跳过; - 如果r2 > r1,此时更新新的区间右边界值right = r2;
- 此时如果r2 <= r1,说明
- 如果l2 > r1,说明下一个区间和现在的区间不重合,直接把现在的结果区间
最大值 <= M 的子数组个数
给你一个数组
arr,请你找到内部元素最大值<= M的子数组个数?例如:
[1,5,2,3,4]中最大值<= 3的子数组有[1]、[2]、[3]、[2,3],共四个。注意,子数组是连续的。
思路:
- 每一个子数组都有一个结尾,我们可以通过枚举子数组结尾元素位置,来计数;
- 对于以
arr[i]为结尾元素的一系列子数组:- 如果
arr[i]本身> M,则没有满足要求的子数组; - 如果
arr[i]本身<= M,则以arr[i]为结尾的满足要求的子数组个数,等于从i位置向前(包含i)满足<=M的连续元素个数.
- 如果
function cal(arr, M) {
let res = 0;
let cur = 0;
for (let i of arr) {
cur = i > M ? 0 : cur+1;
res += cur;
}
return res;
}
// cal([1,5,2,3,4],3);
// 4
矩阵旋转
一个矩阵旋转(顺时针、逆时针),可以转化成水平、垂直翻转或沿对角线翻转的组合。
- 如果旋转90度,可以转化为一次沿水平、垂直的翻转+一次沿对角线的翻转;
- 如果旋转180度,可以转化为两次沿水平、垂直的翻转。
消除相同的数问题
消除相同的两个数
可以考虑使用位运算中的异或运算,对完全相同的两个数进行消除。
异或: 位相同则返回0, 否则返回1。
- 如果两个数
a === b,那么a ^ b === 0; - 任何一个数
a,它与0异或运算后,仍然是它本身,a ^ 0 === a。
消除相同的多个数
问题类型: 一个数组中,只有一个数x出现的次数为1,其他数都重复出现n次,请找出这个单独的数。
基本思路:
- 按位思考,对于每一个数的每一位,因为只能是1或0,对于重复出现的n个数,它们在这一位上的加和只能是
n或0; - 所以对于除单独的数
x外,其他的数在每一位上的加和只能是nk(k >= 0 && k <= n); - 考虑单独的数x,全部数在每一位上,加起来的和只能是
nk+1或nk; - 因此,对全部数每一位进行加和,然后用
n取余数,余数就是要找的单独数x在该位上的实际值。
// 在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
var singleNumber = function(nums) {
let res = 0;
let cur = 1;
for (let i=0; i<31; i++) {
let s = 0;
for (let n of nums) {
if ((n & cur) !== 0) {
s += 1;
}
}
res += cur * (s % 3);
cur <<= 1;
}
return res;
};
位运算判断纯字母字符串是否含有重复字母
因为字母一共只有26个,使用二进制数字的每一位(0~25)表示一个字母,最大为226-1不会超出JS数字上限。
设初始掩码为mask=0(全0),当字母存在时置对应位为1。具体操作为获取字母在字符串abcdefghijklmnopqrstuvwxyz的索引i,然后执行以下操作:
let cur = 1 << i;mask |= cur;
例如:acde对应的二进制掩码后五位为11101(其余全为0)
当判断字符串a与b是否有重复字母时,取a、b的掩码mask_a和mask_b,对它们执行与操作&:
- 如果为0,则没有重复字母;
- 否则含有重复字母。
取余操作
对较大的幂值进行取余操作
求
a ** b % mod,假设a ** b是一个较大的值,超出了JS数字的表示范围。
使用一个for循环即可。
let res = 1;
for (let i=0; i<b; i++) {
res *= a;
res %= mod;
}
概率问题
按照权重随机选取元素
给定一个权重数组
w,每个位置i上的值w[i]代表i元素的权重值,目标是按照权重的大小,随机选取一个元素位置t。需要保证权重值越大,被选取的概率越大。
思路:
- 要随机选取,一定要用到随机数API
Math.random(),但是它只能在一个区间内均匀选取; - 要按照权重选取,我们需要将这些权重转化为区间长度,这样在区间内均匀随机选取一个位置,判断其在哪一个区间内,就可以实现按权重选取一个元素了;
- 具体地:
- 从
0开始,我们将w[i]转化为区间长度,则i位置对应的区间右边界为[0,i]区间内w[i]的前缀和,进行预计算,w[i]前缀和组成的数组假设为pre[i]; - 设
w[i]的总和为s,则我们在[0,s]范围内随机均匀抽样,选取一个随机数t; - 二分查找,找到第一个
pre[i] >= t的位置i,则i是我们按权重随机选择的结果。
- 从
使用rand7生成rand10
如何使用一个随机生成
[1,7]的范围内整数的函数rand7(),实现一个在[1,10]均匀采样的函数rand10() ?
这个问题更精确的描述是:使用一个较小范围的均匀随机离散点生成器,实现一个更大范围的均匀随机离散点生成器?
解决思路:
- 可以多次执行提供的随机函数,生成更多的随机结果;
- 为保证结果是均匀的,我们不能让两次随机产生的结果互相有叠加,因为这样会让概率值发生变化;
解决方法:
使用rand7()生成一个二维坐标点。
- 调用两次
rand7(),分别当做横坐标r和纵坐标c; r和c一共可以表示7*7 = 49个二维格子位置,将格子从上到下、从左到右进行编号1 ~ 49;- 计算出抽到的格子编号
idx; - 因为
49无法整除10,对于后面的[41, 49],如果抽到,我们拒绝采样,直接重新再采样一次,直到抽到的数idx <= 40; - 返回
(idx - 1) % 10 + 1。(为了让取模后的起始点为1而不是零)

小技巧: Tips
- 集合中选取元素组成目标和
tar的问题,可以转化为给集合中的元素添加符号的问题:- 抽取若干元素凑成目标和:转化为在原集合中的每个元素前面添加
+1或0因子; - 将集合中的元素,分为各自加和为目标和的两组:转化为在原集合中的每个元素前面添加
+1或-1因子,使得加和结果为0; - 选取集合中的部分元素,分为各自加和相同的两组:转化为在原集合中的每个元素前面添加
+1、-1或0因子,使得加和结果为0;
- 抽取若干元素凑成目标和:转化为在原集合中的每个元素前面添加
- 判断数组的前
n个元素arr[0] ~ arr[n-1]是否与索引值一一对应(也就是元素取值范围是[0, n-1]):- 从前向后遍历原数组,记录最大值
max,如果max === i,则[0,i]区间满足索引与元素一一对应。
- 从前向后遍历原数组,记录最大值

